Introduction
Welcome to the first lab of CSCI 3308! This lab has as its goal to introduce you to the Unix environment that you will be using in lab this semester.
After this one, there will be a new lab released every two weeks with your work due by the end of the second lab session. You are expected to work together with your lab partner to produce a single assignment that will be submitted for the two of you. The lab will be designed to encourage you to use some of the pair programming techniques discussed in lecture. So be on the lookout for ways in which one person can take the “driver's seat” while the other is thinking about where you are going and what tests can be written to help you get there.
The first thing you need to do is to get a terminal window open so you can try out some of the commands discussed below. Ask the TA if you need help in launching a terminal window. You will eventually need to open a second terminal window to create a document that stores the answers to the questions that will appear below.
Man
UNIX systems contain on-line manuals called man pages that are accessed through the program man. To find out how to use man type:
$ man man
Those of you already familiar with man pages may still want to re-read man's man page to learn about advanced features that you may not already know. Regardless, you must know enough about man to answer the following questions.
- What command would find the
manpage forexitin section 2 of the manual? - What command would list all the
manpages related to the keywordnetwork? - Why do some commands appear in multiple sections of the manual. For instance, try executing the commands
man 2 openandman 3 open.
Note: You can find additional information about this command at Wikipedia's entry for the Unix manual.
Text Editors
Unix systems feature a lot of different text editors, such as pico, emacs, and vi (also know as vim). We do not require a specific text editor in this class, so use whatever program suits your working style best. To get you started, you can learn more about these programs by accessing their on-line help and/or tutorials.
| Program | Accessing Help | Accessing Tutorial |
|---|---|---|
emacs |
Launch emacs and then type Ctrl-h |
Launch emacs and then type Ctrl-h t |
vi |
Launch vi and type :help | Launch vimtutor |
pico |
Launch pico and type Ctrl-G | N/A |
Of course, you can always get more information on the Web by performing a search in your favorite search engine using, e.g., a phrase like "pico tutorial".
The Kernel and the Shell
It is important for you to understand how the UNIX operating system is organized. When you are logged on, the computer is running something called a kernel and something else called a shell. These are separate things (as shown in Figure 0), and we will discuss them one at a time.
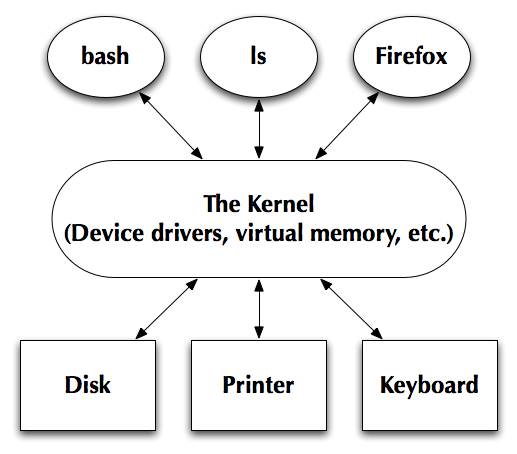
Figure 0: Unix Architecture (Simplified)
The kernel controls all access to hardware. Whenever a key is pressed, the mouse is clicked, or something is printed to the screen the kernel must be involved. However, the kernel is a very low level component. Users don't interact with it directly. It does not print your prompt, and it does not interpret the commands you type. You can interact with the kernel when you write programs, for example when you open and close files.
You can call the kernel directly with system calls, but normally you don't do this. Instead, you call a library procedure which calls the kernel for you. Look up the man page for open in section 2 of the manual, and the man page for fopen in section 3 of the manual. Both of these open files. Open is a system call directly to the kernel, and fopen is a library procedure. Many programs use fopen because it handles details automatically and presents a simpler interface. You can think of calling the kernel directly as low level programming like assembly language, and library procedures as high level programming like C++.
Strictly speaking, the UNIX operating system consists of just the kernel. However, there is another program called the shell (labeled bash in Figure 0, but keep in mind that there are many different shells to choose from) that is very important. The shell is the program that prints your prompt, and starts up programs when you type their names. The shell is a normal program like a Web browser or a text editor. It has to use the kernel to accomplish what it does. For example, here's what happens when you type ls *.cxx to print all .cxx files:
- Each time you type a key, the kernel receives a hardware interrupt stating that a key has been pressed. It places that character in an input buffer for the shell. The kernel has no idea that the two characters
lsare the name of a program that you want to run. - The shell reads its input buffer until it gets to the end of the line. (You read from the input buffer in your C++ programs when you use the
cincommand.) The shell interprets the line as words separated by spaces. The shell assumes that the first word,ls, is a program that you want to run. The shell has to ask the kernel if a program namedlsexists, and if so, to please start it up. - The shell also interprets
*.cxx. The shell asks the kernel for the names of all the files in the current directory. The shell knows that*matches anything, so it checks each one to see if it ends with.cxx. If so, it passes the file name on tols. - The
lsprogram receives a list of file names.lshas no idea that you ever typed*. It prints out each of the files and exits. - The shell prints another prompt, and waits for the user.
It is important to know what parts of the computer do what in case something goes wrong. At some point, you may think you have a bug in your program when in fact the problem is that the shell can't find your program, or there is a problem with interpreting your arguments.
One final point is that you can run many shells, but there is only one kernel. If you have two windows open, and each window has a prompt, then you have two shells running, but they are both talking to the same kernel. Several people can be remotely logged on to a single computer. Each of them could have several shells, but they would all access the same kernel.
There are also several types of shells. To find out what shell you are using type echo $shell.
- What shell are you using?
Note: the question above should have the number "4" in front of it. If it doesn't, then the Javascript that I'm using to number questions in this lab is failing in your browser. You can either keep track of the question numbers yourselves as you move through the lab, or, try viewing this lab in a different browser.
This semester, we will be teaching and using the bash shell. If you are currently running a different shell, be sure to invoke an instance of the bash shell by typing bash at your prompt.
Shell Variables and Environment Variables
To make your life easier, the shell has the ability to store variables. Each variable holds a value just like variables in an ordinary programming language. Unlike most programming languages all variables are of type string. It is legal to type x=25 in your shell (try it now), but this sets the value of variable x to be the string "25", not the integer 25. To read the value of a variable precede its name with a dollar sign. For example, $x. When the shell sees a dollar sign, it looks this word up to see if it is the name of a variable. If the word is a variable name, the shell replaces the word, including the dollar sign, with the value of the variable. If the word is not a variable name, the shell prints an error message.
Type the following:
$ word=quiet
$ echo word
$ echo $wordNote: there should be no spaces before or after the = symbol in the first command.
echo is a command that prints out whatever it reads in. When you typed echo word the echo command read word
and printed word
. When you typed echo $word the shell saw $word
and replaced it with quiet
. Then the echo command read quiet
and printed quiet
. The effect was exactly as if you had typed echo quiet.
Now type:
$ echo $wordly
$ echo "$word"lyIn the first command the shell couldn't find the variable wordly
. The problem was that the shell tries to get the biggest word it can, stopping only for spaces or other special characters, so it didn't try to match $word
. Quotes are one of the special characters that the shell recognizes so the second command tells the shell to look up $word
, and then add ly
to the end producing quietly
.
If you need to assign a variable a value that consists of more than one word, simply enclose the value in double quotes. For example:
$ car="Honda Civic"
$ echo $carVariables can also function as one-dimensional arrays. You can create an array using several different methods. One method is to assign individual elements of the array, one element at a time. Like this:
$ colors[0]=red
$ colors[1]=green
$ colors[2]=blue
$
$ echo ${colors[0]}
$ echo ${colors[1]}
$ echo ${colors[2]}
$
$ echo ${colors[*]}
$
$ echo ${#colors[*]}The example above creates an array with three elements and shows how you can access individual elements as well as display the entire list at once and learn the length of the array.
A second method for creating arrays is to define the array all at once, using the following syntax:
$ colors=( red green blue orange purple )
$ echo ${colors[2]}There are two types of variables, shell variables, and environment variables. (To see a list of variables for the current shell, execute the set command on a line by itself with no arguments.) There are only two major differences that you need to be aware of between these types of variables. The first difference is that environment variables are copied to any new child processes created from the current process while shell variables are not. For this reason environment variables are often used like global variables and shell variables are used like local variables. To distinguish them, environment variables are typically given names in all capital letters, while shell variables are given lower case names.
The other difference between shell variables and environment variables is how they are created. By default, a variable is a shell variable and will function as a local variable within the shell that created it. To create an environment variable, you need to use the export command. You can either create a shell variable and then export it, or you can create a new environment variable directly with the export command. Try the following:
$ x=23
$ y=42
$ export y
$ bash
$ echo $x
$ echo $y
$ echo $z
$ exit
$ export x
$ export z=65
$ bash
$ echo $x
$ echo $z
$ exit- Explain what is being demonstrated by the commands above.
Type the following statements:
$ a=the
$ b=blue
$ export C=deep
$ b="$C $b"
$ C=sea
$ export PHRASE="$a : $b : $C"- List all of the variables given above, and say whether each is a shell variable or an environment variable.
- What are the values of
bandPHRASEafter executing the above statements?
In the same window in which you typed the above commands, type bash. This will start a new instance of bash which is a child process of the shell that executed the above commands. Now type:
$ echo $b
$ echo $PHRASE- What happened and why?
Configuring Your Environment
Now that you know about environment variables, we are going to take a slight detour from the lab to configure your environment to contain two environment variables that we will use throughout the semester. If you have an environment variable that you would like to have available every time you start a new instance of a shell, you place its definition in your <~/.bashrc> file. This file gets read each time bash starts up. Open this file in your favorite text editor and add the following two environment variable definitions at the bottom:
export ARCH=$(arch)
export C3308=/home/courses/current/csci3308The first variable definition invokes a program called arch and stores the result of that program in an environment variable called ARCH. On lab machines, the value of this variable will be i686. The second variable stores the path to a directory that we will use throughout the semester to store files needed for the labs. Note: we could also write the above definitions like this:
ARCH=$(arch)
C3308=/home/courses/current/csci3308
export ARCH C3308Use whatever style you prefer. Once you have finished editing your file to contain these definitions, save it, and type the following:
source ~/.bashrcOkay, you are now ready to continue with the lab.
Directory Paths
In UNIX the location of a file or directory is given like this </usr/local/X11/doc/FAQ.txt>. This is essentially a list of directory names separated by slashes, and the last name is the name of a file. You can think of the file system as a tree. Each directory is a node in the tree. It has pointers to its parent, and all of its children, but does not know anything about other nodes in the tree. To find this file, FAQ.txt, the kernel cannot just go directly to its immediate parent directory, doc, because it does not know the location of that directory on the hard disk. The kernel only knows the location of one directory, /, also called the root directory.
To find </usr/local/X11/doc/FAQ.txt> the kernel goes to /, and looks up the location of usr. Then it goes to usr and looks up the location of local, and so on. This hopping from one directory to another has been described as following a path of directories. For this reason, </usr/local/X11/doc/> is said to be the directory path to the directory doc that contains the file FAQ.txt.
This leads us to a very confusing naming convention in UNIX. There is an important environment variable named PATH, also called the command path. This variable is a string that contains a list of directory paths separated by colons. For example:
/usr/local/bin:/usr/bin:/bin:/usr/local/sbin:/usr/sbin:/sbin:/usr/share/binThis particular value for the PATH environment variable consists of seven directory paths. The confusion that can occur here is that people will sometime refer to the PATH environment variable AND a directory path using just the word path
. Just be clear that the former is a list of directory paths, while the latter refers to the location of a specific directory in the file system.
The PATH variable is used to tell the shell where to look for commands that a user types. Thus, if I type the command passwd, then, given the value above, my shell would look for the passwd command first in the directory </usr/local/bin>, then in </usr/bin>, and so on until it had looked in all seven directories. If it find the command in one of those directories, it executes it, otherwise it prints a message like the following:
$ foo
$ bash: foo: command not foundWhen I said that the kernel only knows the location of the root directory, that was not entirely accurate. It also stores a few other convenient directories where you can start directory paths. The first of these is the current working directory. When a directory path does not start with a slash it is assumed to start in the current directory. Directory paths that start in the current directory are called relative paths because the location referred to is relative to where you are at the time, and can change if you change directories. In contrast, directory paths that start at the root directory are called absolute paths because the location referred to does not change if you change directories.
There is a third starting point for directory paths called your home directory. The character ~ represents the current user's home directory. To specify a different user's home directory type ~username. You can also specify your home directory with the environment variable HOME. Type echo $HOME to see what its value is. Using ~ does not work in every situation. If you run into problems when using it, try using $HOME instead.
Finally, we should mention that there are two special notations that can be used in directory paths. The first notation is . which is shorthand for the current directory and the second notation is .. which is shorthand for a parent directory, i.e. moving up a level in a directory tree. So, if you wanted to invoke the command foo that was located in the current directory, you would type the following:
./fooIf you wanted to invoke the command foo that was located in a directory two levels above the current directory, you would type:
../../fooIt is very important that you understand this material on directory paths. If you have any questions about this topic, be sure to call the TA over to your workstation and ask away!!
The Command Path
When you type a command you are actually typing the filename of an executable file. As briefly mentioned above, to run that command the shell must be able to find the file. The way to tell the shell where to look for executable files is through the PATH environment variable (aka the command path). Type the following:
echo $PATHYou should see a list of directories. Most of them probably end with bin. Bin stands for binary and is a common name for directories used to hold executable files. Now type:
export PATH=""
echo $PATH
lsOh, no! The shell is broken, you can't even list the files in your directory! Actually, the shell isn't broken, you just have to understand how it works. There is nothing special about ls, it's just a program. It has an executable file somewhere in the file system. When you want to list the files in your directory you type ls. The shell sees this, and looks for an executable file named ls. Where does it look? It looks in the directories listed in your PATH variable. When you executed PATH="" you set your path to an empty list. The ls program is still there, but your shell doesn't know where to find it. Luckily there is a way to get your path back. Type:
export PATH="/usr/bin:/bin"
source /etc/profile
source ~/.bash_profile
lsYou should recognize <~/.bash_profile> as a directory path that starts in your home directory. When you see this you should think, There is a file named
. This file is called a startup file, and it is where the shell gets your path each time you log in. (Well, almost, you also need to source the .bash_profile in my home directory</etc/profile> initialization file that is also read by the shell each time you log in.) Essentially, you just re-ran your startup file(s) to reset all of your variables including your path.
Changing the Command Path
Lets say you have a program that you want to run, but it is in a directory that is not in your path. You can change your path to include the desired directory. Type the following:
hello
PATH="$PATH:$C3308/arch/$ARCH/bin"
helloThe executable file hello is located in the directory $C3308/arch/$ARCH/bin. The shell couldn't find it until you put that directory in your path. Note: The second command above is similar to saying x = x + 1 in a program. When we say PATH="$PATH:foo" we are adding the directory foo to the end of our path. If we say PATH="foo:$PATH", we are adding the directory foo to the start of our path.
Now that we modified the PATH environment variable our current shell can execute the hello program with no problems. However, if you were to logout and then log back in again, you would no longer be able to execute the hello program.
- Why not?
This is where your <~/.bash_profile> file comes in. This file is read by bash when you first log in, and is a perfect place to add any directories to your command path that you intend to use on a regular basis. All you need to do is to place a command like PATH="$PATH:foo" to have the directory permanently added to your PATH environment variable. Go ahead and add the directory <$C3308/arch/$ARCH/bin> to your PATH environment variable by editing your <~/.bash_profile> file. Be sure to add this statement after the place in the file which reads your <~/.bashrc> file and before the export PATH statement.
- Why is it important to add this particular directory after the
.bashrcfile has been executed?
After you have made this change, logout, log back in again, and then verify that the hello program is located in your command path. You can do this in bash either by typing the name of the command and attempting to execute it, or by executing either of the following commands:
$ type -p hello
$ which helloBoth commands should print the path that shows where the hello program is located. (If not, have the TA help you figure out why and then fix the problem.)
Searching the Command Path
The next thing to understand is how the shell searches your path. The shell starts with the first directory in your path. If that directory contains a file with the correct name, it tries to run it. If not, it goes on to the next directory in your path, and so on. There is a different version of hello in the directory $C3308/bin. Add this directory to your path. Now type the following:
$ $C3308/bin/hello
$ $C3308/arch/$ARCH/bin/hello
$ helloFirst, you typed out the entire path to the files and the shell should have run the copy of hello that you specified. When you just typed hello the shell ran the copy in the directory that comes first in your path. There are two useful commands for looking for programs in your path, type -p and type -a. Type the following:
$ type -p hello
$ type -a hellotype -p prints out which program will be run if you just typed its name with no directory path. type -a lists all copies of a program with that name in your path. If there are multiple copies of a program with the same name, and you care which one gets run, you should use the type -a command to determine whether you can simply type the program's name to execute it or if you will need to type the program's full directory path.
Your Directory Structure
It is a good idea to have an extensive directory hierarchy under your home directory to organize your files. There are no absolute rules about the best way to organize a directory hierarchy. Usually, you design your own hierarchy, and the most important thing is how useful it is to you. However, sometimes there are other considerations. For example, if you are working for a company, your manager might want everyone's directory hierarchy to be set up the same so that things are easy to find even under another person's home directory. In this class we will be simulating this situation where your directory hierarchy is specified for you by a manager.
In your home directory create a directory named csci3308. This directory <~/csci3308> will be called your class home directory. All files we create in this class will be placed under this directory, and this directory should only be used for this class. The reason for this is so that our files will not interfere with your own personal files, or with files from other classes. Also, for many of the labs we have files configured to work assuming this directory structure.
There is an important difference between $C3308 and ~/csci3308. There is a directory for the class called csci3308 located at the path specified by $C3308. Many of the files you will use for this class will come from this directory. However, you also have a directory named csci3308 under your home directory. The directory path to this is <~/csci3308>. This means ~, your home directory, /, a subdirectory of your home directory, and csci3308, the subdirectory is named csci3308. This is different than $C3308 and you should understand this difference and keep these two directories straight in your head.
Create subdirectories of your class home directory as shown in Figure 1. We will discuss the purpose of each directory next.
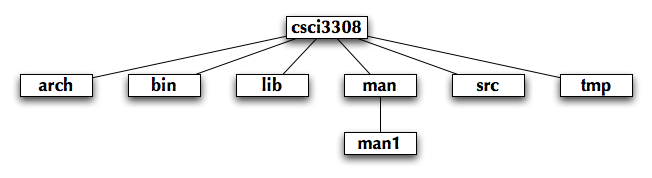
Figure 1: Directory Structure
arch-
Occasionally you will find yourself in an environment in which there are computers of several different architectures. Earlier in this lab, we used the
archcommand to store the name of the architecture of the lab machines in ourARCHenvironment variable. (Note: our lab consists of machines that all share the same architecture. Later in the semester, we will make a machine with a different architecture available so you can learn the benefits of creating architecture-specific directories.)Certain files such as binary executable files will only work for a particular architecture. These are referred to as architecture-specific files. The
archdirectory is where you will keep architecture-specific files. Create a subdirectory in yourarchdirectory for the architecture of the lab machines. You can do this by executing the commandmkdir $ARCHwithin thearchdirectory.Each architecture-specific directory also needs certain subdirectories. Under the directory that you just made, create the directories shown in Figure 2.

Figure 2: i686 Directory StructureWe now provide a brief discussion of each of these directories.
arch/i686/bin-
A
bindirectory is where you store executable files. Because thisbindirectory is under thearch/i686directory it stores architecture specific executable files for thei686architecture. These files are also called binaries, hence the namebin. These kind of files are the normal programs that everyone knows and loves.Unfortunately, binary files only work for one architecture. Imagine that you had written a very useful program in C++, and you compiled it on an
i686machine. The program would work great and do its useful thing on ani686machine, but if you tried to run it on asun4machine you would probably get a message like
To solve this problem you need to compile the program on aExec format error. Wrong Architecture.sun4machine, but this will create a new executable file with the same name as the old one. If you create it in the same directory it will overwrite the old program, and you will no longer be able to use the program on ani686machine without recompiling again.Rather than recompile the program every time you switch architectures you should have multiple copies of the same program that work on different architectures. These copies have to be placed in different directories. That is the purpose of architecture-dependent directories.
You want the program to be in your path, but which copy? You have multiple copies of the program in different directories. Which directory should be in your path? The string
…/arch/$ARCH/binsolves this problem. The variableARCHautomatically selects thebindirectory that contains programs that will work on your current architecture. So, please add$HOME/csci3308/arch/$ARCH/binto your command path by editing your~/.bash_profilefile. arch/i686/build-
When you compile programs, they often create many intermediate files that are only used in the compilation process. For example, to compile a C++ program, the compiler first creates a
.o(object) file for each.cppsource file. Then these.ofiles are combined to create an executable file. Once the executable file is created the .o files are unnecessary to running the program and can be deleted. If the program is undergoing changes then keeping.ofiles around can speed up compiling the program because only those.cppfiles that change need to generate new.ofiles. Usually,.ofiles are kept around while a program is being changed, but are deleted when the final version is compiled.A naive approach to keeping intermediate files around would be to compile the program in the bin directory where the executable should go. Unfortunately, this creates some problems:
- Intermediate files clutter the bin directory and make executable programs harder to find.
- When you want to delete intermediate files it is harder to clean up all of the unnecessary files without deleting files you want.
- If two programs both create an intermediate file with the same name they will overwrite each other.
To solve the first two problems, programs are compiled (built) in the build directory, and to solve the third problem each program is given its own subdirectory under the build directory. The program is built in that directory, and all of the intermediate files are created there. When the final version of the program is completed the executable is copied (installed) to the
bindirectory, and the entirebuilddirectory for that program can be deleted without worrying about deleting anything you need. arch/i686/includeandarch/i686/lib-
These directories hold libraries of functions that can be used and reused by different programs without rewriting, or even recompiling, the library. This topic will be discussed in more detail later in the semester.
arch/i686/man-
This directory holds man pages that are architecture-specific. Believe it or not, some programs work differently on different architectures, and so need different man pages.
arch/i686/tmp-
This directory holds any architecture specific temporary files.
bin-
This directory holds files that are executable, but are architecture-independent. An example of this is a shell script; such scripts are not compiled; instead they can be run on any architecture via an interpreter.
lib-
This directory holds reusable components that behave like libraries, but are not architecture-specific. An example would be a high score file for a game. You want the program to use the same high score file no matter what architecture you are on.
man-
This directory holds
manpages. Mostmanpages are stored in directories where you do not have write access. Thus, you have a problem if you download a new program and you want to store and access itsmanpages. The solution is to store itsmanpages in your ownmandirectory. Under themandirectory create a directory calledman1. In this directory create a text file namedsimple.1containing the text
or something to that effect. Now type:This is my man page.man simple man -M $HOME/csci3308/man simpleIn this case, the
manprogram was only able to find ourmanpage when we told it where to look using the-Mflag. This is because themanprogram searches for a program's manual pages via a very interesting and powerful convention. In particular, themanprogram will examine the command path and search formandirectories in the following way: for each directory in the command path, themanprogram will look for amandirectory either as a subdirectory of the current directory or as a subdirectory of the current directory's parent directory. (Themanprogram is also configured via the</etc/man.config>file.)This means that we can get the
manprogram to automatically search for manual pages in our$HOME/csci3308/mandirectory by adding our$HOME/csci3308/bindirectory to our command path. In this case, the desiredmandirectory will be a subdirectory of the relevantbindirectory's parent directory. So, try adding$HOME/csci3308/binto your command path by editing and sourcing your~/.bash_profilefile. Then run the commandman simpleagain, to test whethermancan find yoursimple.1file automatically. Note: via a quirk in this system, you do not actually need an executable file calledsimplein the$HOME/csci3308/bindirectory, although usually you will have an executable associated with a particular manual page.Important: with this last edit to your command path, you should have a
~/.bash_profilefile with the following lines in it (located somewhere before theexport PATHstatement):# CSCI 3308 Related Paths PATH=$PATH:$C3308/arch/$ARCH/bin PATH=$PATH:$C3308/bin PATH=$PATH:$HOME/csci3308/arch/$ARCH/bin PATH=$PATH:$HOME/csci3308/binIf you do not have these four lines or you made a mistake while entering them during the course of this lab, then edit your
~/.bash_profilefile to make sure you have these four directories added to your command path, specified in this fashion and in this order. src-
This directory holds source code for programs you build. You want to keep source code, intermediate files, and executable programs separate for all of the reasons listed in the description of the build directory above. Like the build directory, the source directory will have a subdirectory for each program in case two programs have files with the same name.
tmp-
This directory holds temporary files. You should feel free to remove all of the files in your
tmpdirectory at any time. Consequently, you shouldn't put anything in yourtmpdirectory that you don't want deleted.
Your First Shell Script
A shell script is an ordinary text file containing a list of shell commands. Every time the script is invoked, the command-line interpreter runs the commands listed in the file. Use your favorite text editor to create a new file, called foo, containing the following text:
#!/bin/bash
echo The current date and time is $(date).- This shell script is an architecture-independent executable file (because the
bashinterpreter has been ported to many different architectures). In what directory should it be placed?
Please place your script in the correct directory. You now need to change the script's file permissions to allow it to be executed. Type the following:
chmod u+x fooIf your shell script is in the right directory it should be in your path and you can access it from anywhere. Use type -p to verify that bash knows about your script, you can then type foo to run your script.
Wrapping Up
You have covered a lot of ground in this lab, from learning about Unix, its kernel, bash, shell variables, and more. There is more to learn of course. But, if you have mastered the material in this lab, you will be ready to tackle the remaining labs in this class. You should continue to learn about bash on your own by covering the material presented in chapters 13 and 14 of your reference text book, Unix Shells by Example, 4th edition